Why Observability for Voice AI Is Non-Negotiable?

Mai Medhat
CEO & Co-founder @ Tuner
Voice AI is getting dramatically better. Models are faster, latency is dropping, accuracy is improving, and costs are coming down. Enterprises are more ready than ever to adopt Voice AI across support, sales, and operations.
And yet, the industry keeps repeating the same pattern. Teams deploy voice agents with impressive demos and strong test results. Early pilots succeed, leadership gets excited, and rollouts begin.
Then, quietly, things start to unravel. Performance degrades, customer satisfaction dips, and edge cases pile up. Months later, the system is scaled back… or shut down entirely.
This isn’t because Voice AI doesn’t work. It’s because Voice AI behaves very differently from traditional software.
This Isn’t Hypothetical. It’s Already Happened.
We’ve already seen what happens when Voice AI is deployed without deep production visibility.
McDonald's rolled out AI-powered drive-thru ordering across hundreds of U.S. locations, then shut it down after inconsistent real-world performance across accents, noise, and ordering styles.
Google faced legal action after Assistant mistakenly activated from false wake words, recording unintended conversations.
These weren’t isolated bugs or bad demos. They were production failures that emerged gradually and surfaced too late.
Voice AI Doesn’t Fail Loudly. It Fails Gradually (Sometimes Silently)
Traditional software failures are obvious. A service goes down, an alert fires, engineers respond.
Voice AI failures are different. They emerge slowly and unevenly:
A model update drops accuracy 5% for a single intent.
Latency increases only in one geographic region.
One accent group sees more interruptions.
Users start repeating themselves due to subtle ASR drift or KB gaps.
Containment rates decline week over week.
No single issue looks critical. But together, they erode trust, and by the time complaints show up, the damage is already done.
Without continuous observability, these patterns are invisible.
Testing Covers a Tiny Fraction of Real Behavior
You can run hundreds of test scenarios. Production will still surprise you.
Real users introduce variables you can’t fully simulate:
Regional and non-native accents.
Background noise (cars, kitchens, call centers).
Emotional speech: frustration, sarcasm, hesitation.
Code-switching mid-sentence.
Interruptions, corrections, ambiguous phrasing (“the usual”).
And yes, users deliberately trying to break the system.
The behavioral space is exponential. Testing samples a sliver. Production is where Voice AI actually gets tested.
Production Is the Only Reliable Quality Signal
Testing tells you how the system behaves in controlled conditions. Production reveals:
Turn-taking breakdowns.
Latency compounding across multi-turn conversations.
ASR drift after model or traffic changes.
Intent confusion that only appears at scale.
Long-tail failures triggered by real user behavior.
This gap, between “works in testing” and “works at scale”, is where most Voice AI deployments fail.
According to the Deepgram 2025 Voice AI Report, while over 80% of organizations have experimented with voice agents, only 21% report being “very satisfied.” That gap isn’t about ambition or effort. It’s about visibility.
What Continuous Observability Actually Means for Voice AI
Observability in Voice AI isn’t just logs and dashboards. It means having continuous answers to questions like:
Is intent accuracy drifting for a specific segment?
Are interruptions increasing after a model change?
Did latency spike after an infra update?
Are users repeating themselves more than usual?
Is a new failure pattern emerging that we’ve never seen before?
This requires more than periodic reviews. It requires live evaluation against production traffic.
What This Looks Like in Practice
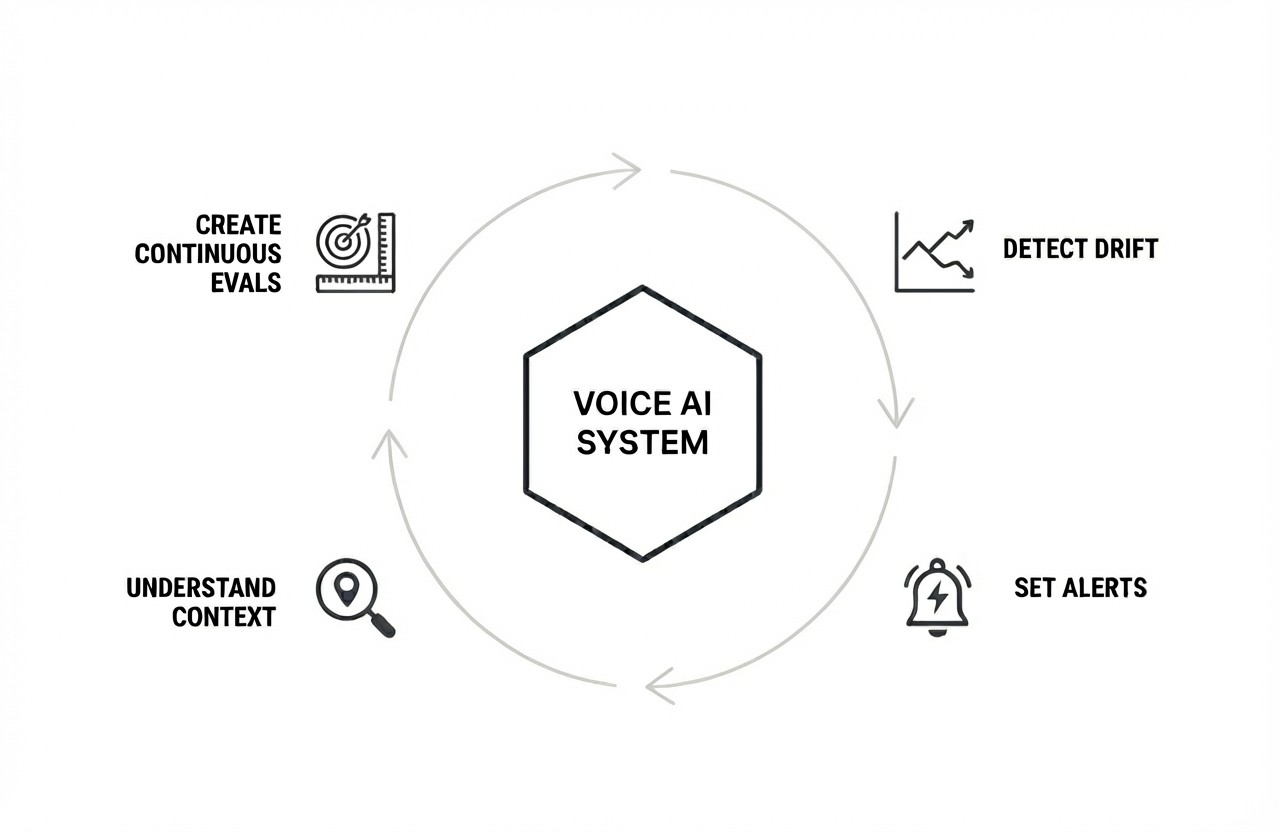
In practice, this means continuously evaluating real conversations, detecting when behavior changes, and reacting before issues reach customers.
This is where an observability layer like Tuner comes in.
Tuner sits alongside Voice AI systems in production and helps teams turn live traffic into actionable signals.
Continuous evals
Teams define what “good” looks like—intent accuracy, latency, containment, interruptions, task success—and evaluate these signals continuously on real conversations, not just test data.
Drift and anomaly detection
Tuner surfaces gradual degradation, segment-specific issues, and unexpected behavior changes that are easy to miss but costly over time.
Set red flags and real-time alerts
Instead of waiting for complaints, teams get alerted when metrics move outside expected ranges—latency spikes, intent confidence drops, or new failure patterns start trending.
Understand failures in context, not just metrics
When something breaks, teams can see where it happened, who it affected, and under what conditions—turning incidents into learning, not guesswork.
The goal isn’t to catch every edge case.
It’s to make production behavior visible, so systems can improve continuously, not reactively.
Closing the Production Feedback Loop
Voice AI is no longer an experiment. It’s becoming core infrastructure, and infrastructure without observability is a liability.
If a voice system handles real customers and real revenue, it needs production-grade discipline: continuous measurement, clear quality signals, and real-time alerts.
Observability is how the loop closes, and how Voice AI becomes infrastructure.




Tuner helps voice AI teams test, monitor, and debug calls before issues reach users.